Career Chat¶
This is a simple implementation of RAG to chat over my career history.
Note:
- VectorDB is not used. FAISS (vector index) used because career data changes less frequently and also keeps it lightweight since index files can be loaded directly from the file-system
- Local LLM took too long to compute, hence this notebook has been revised to use OpenAI LLM
Setup¶
With the following contents of pyproject.toml created by uv:
[project]
name = "career-chat"
version = "0.1.0"
description = "Career Chat with RAG - chunks and FAISS indexes"
readme = "README.md"
requires-python = ">=3.12"
dependencies = [
"faiss-cpu>=1.11.0.post1",
"langchain-openai>=0.3.28",
"langchain-text-splitters>=0.3.8",
"markdown-it-py>=3.0.0",
"numpy>=2.3.1",
"pypandoc>=1.15",
"python-dotenv>=1.1.1",
"sentence-transformers>=5.0.0",
]
[dependency-groups]
dev = [
"black>=25.1.0",
]
Run the following to resolve depedencies
$ uv sync --all-groups
Resolved 76 packages in 7ms
Audited 57 packages in 0.36ms
import os
import re
from langchain_text_splitters import MarkdownHeaderTextSplitter
import json
import numpy as np
from typing import List, Dict, Tuple
from sentence_transformers import SentenceTransformer
import faiss
import openai
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
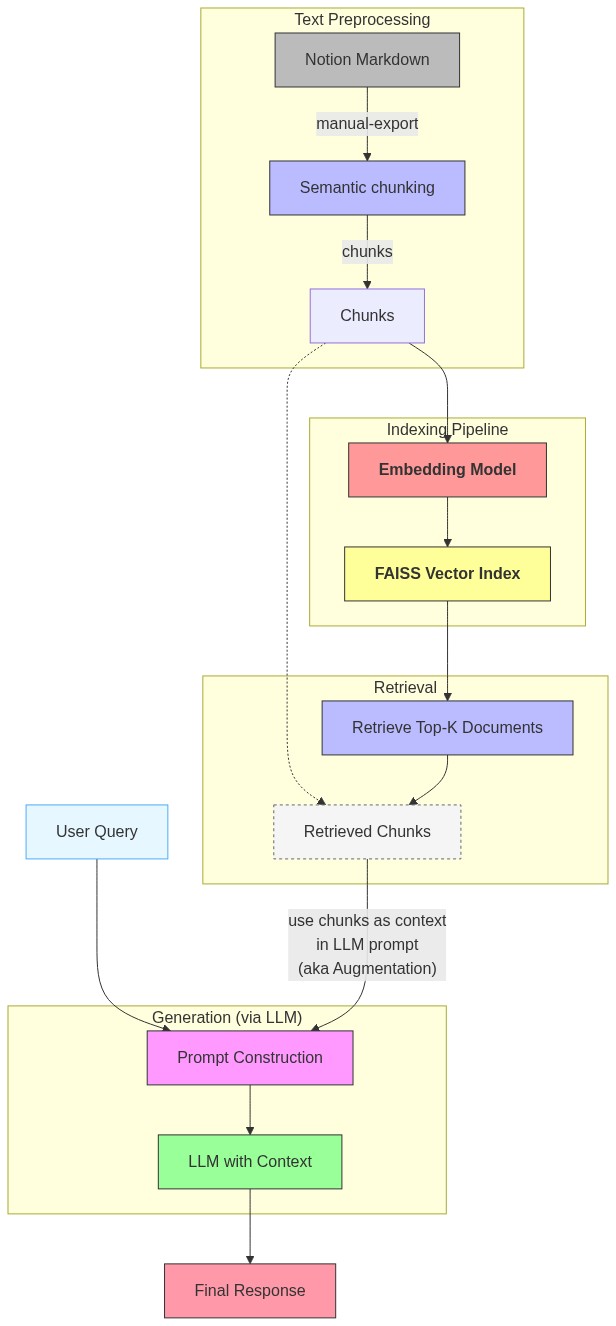
Birds Eye View¶
High level depiction of the entire pipelien
from IPython.display import Image, display
import base64
import requests
graph_definition = """
flowchart TD
subgraph Preprocessing["Text Preprocessing"]
A
B
BC
end
subgraph Indexing["Indexing Pipeline"]
C
D
end
subgraph Retrieval["Retrieval"]
E
EC
end
subgraph Generation["Generation (via LLM)"]
F
G
end
A["Notion Markdown"]:::bold -- "manual-export" --> B["Semantic chunking"]
B -- chunks --> BC
BC[Chunks] --> C
C["<b>Embedding Model</b>"]:::bold --> D["<b>FAISS Vector Index</b>"]
U["User Query"] --> F
EC --> |"use chunks as context<br>in LLM prompt<br>(aka Augmentation)"|F["Prompt Construction"]
style EC stroke-dasharray: 3 3,stroke:#666,stroke-width:1px,fill:#f5f5f5,radius:5px
BC -.-> EC["Retrieved Chunks"]
D --> E["Retrieve Top-K Documents"]
E --> EC["Retrieved Chunks"]
F --> G["LLM with Context"]
G --> H["Final Response"]
D:::component
C:::component
B:::component
A:::component
E:::component
F:::component
G:::component
H:::component
U:::component
classDef component fill:#e6f7ff,stroke:#4dabf7
style A fill:#bbb,stroke:#333
style B fill:#bbf,stroke:#333
style C fill:#f99,stroke:#333
style D fill:#ff9,stroke:#333
style E fill:#bbf,stroke:#333
style F fill:#f9f,stroke:#333
style G fill:#9f9,stroke:#333
style H fill:#f9a,stroke:#333
"""
def render_mermaid(graph):
graphbytes = graph.encode("utf-8")
base64_bytes = base64.b64encode(graphbytes)
base64_string = base64_bytes.decode("ascii")
img_url = "https://mermaid.ink/img/" + base64_string
display(Image(url=img_url))
render_mermaid(graph_definition)
Data Prep¶
My content are in Notion where I have structured it in a specific way. In this example, I have exported the markdown content for the Notion page and will process it to chunk them.
class MarkdownCVChunker:
"""
A specialised chunker for CV in the following format:
```
# Career Profile
# Company
<optional brief>
## Role <dates>
<optional brief>
### Tech work
<optional brief>
Contains tabular information with columns:
Job Title | Work/Project | Technology Used | Skills Applied | Description | Highlights
### <Optional> Non Tech work
<optional brief>
Contains tabular information with columns:
Job Title | Work/Project | Skills Applied | Description | Highlights
### <Optional> Other insights or remarks
# <Optional> Personal Mini Project & Hobbies
list of projects
# Training/Certifications/Courses
bullet list
#Education
Uni degrees etc
```
"""
def __init__(self):
self.splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "H1"),
("##", "H2"),
("###", "H3"),
],
strip_headers=True,
) # Set strip_headers to True
self.table_regex = re.compile(
r"^\s*\|.*\|\s*\n" r"^\s*\|[-|: ]+\|?\s*\n" r"(?:^\s*\|.*\|\s*\n?)*",
re.MULTILINE,
)
def _parse_table(self, table_markdown: str) -> list[dict]:
"""Parses a Markdown table into a list of dictionaries."""
lines = table_markdown.strip().split("\n")
if len(lines) < 2:
return []
headers = [h.strip() for h in lines[0].strip().strip("|").split("|")]
rows = []
for line in lines[2:]:
if not line.strip().startswith("|"):
continue
cells = [c.strip() for c in line.strip().strip("|").split("|")]
if len(cells) == len(headers):
rows.append(dict(zip(headers, cells)))
return rows
def process_cv(self, markdown_text: str) -> list[str]:
"""
Processes the full CV into a list of clean, non-duplicated
Markdown chunks.
"""
final_chunks = []
# The splitter gives us docs where page_content is the text
# between headers, and the headers are in metadata.
initial_docs = self.splitter.split_text(markdown_text)
for doc in initial_docs:
content = doc.page_content.strip()
# Check if this specific piece of content contains a table
table_match = self.table_regex.search(content)
if table_match:
# This is a "Table Container" chunk
# Its only job is to provide rows for granular chunks.
# Extract context from metadata
h1 = doc.metadata.get("H1", "").strip()
h2 = doc.metadata.get("H2", "").strip()
h3 = doc.metadata.get("H3", "").strip()
table_str = table_match.group(0)
table_rows = self._parse_table(table_str)
for row in table_rows:
context_header = f"Regarding my work at **{h1}** as **{h2}**"
if h3:
context_header += f" ({h3}):\n\n"
else:
context_header += ":\n\n"
chunk_md = context_header
for key, value in row.items():
if value and key:
chunk_md += f"- **{key.strip()}:** {value.strip()}\n"
final_chunks.append(chunk_md)
# Check for any text that was *not* the table
# in this container, like an introductory sentence.
non_table_text_in_chunk = self.table_regex.sub("", content).strip()
if non_table_text_in_chunk:
# Prepend the context headers to this narrative text as well
context_header = ""
if h1:
context_header += f"# {h1}\n"
if h2:
context_header += f"## {h2}\n"
if h3:
context_header += f"### {h3}\n"
final_chunks.append(context_header + non_table_text_in_chunk)
elif content:
# This is a "Narrative Chunk"
# It has no table. It's a good semantic unit on its own.
# Reconstruct its full context from metadata for clarity.
context_header = ""
if "H1" in doc.metadata:
context_header += f"# {doc.metadata['H1']}\n"
if "H2" in doc.metadata:
context_header += f"## {doc.metadata['H2']}\n"
if "H3" in doc.metadata:
context_header += f"### {doc.metadata['H3']}\n"
final_chunks.append(context_header + content)
return final_chunks
Test it¶
The markdown file has been placed in cv-data
!tree cv-data/
cv-data/
└── cv-2025-06-01.md
1 directory, 1 file
# Initialize the chunker
chunker = MarkdownCVChunker()
# Process the CV to get Markdown chunks
cv_source_markdown_file_name = "cv-2025-06-01.md"
with open(f"cv-data/{cv_source_markdown_file_name}", "r", encoding="utf-8") as f:
markdown_cv_text = "\n".join(line for line in f)
markdown_chunks = chunker.process_cv(markdown_cv_text)
# --- Output and Verification ---
print(
f"✅ Successfully split the CV into {len(markdown_chunks)} Markdown chunks.\n"
)
from pprint import pprint
for c in markdown_chunks:
print("-" * 20)
pprint(f"{c[:53]} ... {c[-50:]}")
✅ Successfully split the CV into 56 Markdown chunks.
--------------------
('# Career Profile\n'
'Overall, I learn quick, take on chal ... lead by example, get shit done and '
'provide value.')
--------------------
('# Healthdirect Australia\n'
'📍Sydney, Australia \n'
'Sr. Sof ... of Engineering \n'
'Dates: December 4, 2017 - Present')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... compliant to '
'organisational AWS design guidelines\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... e fees. '
'**Trailblazer in LLM based AI adoption**.\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... ard and the '
'service funders from the Commonwealth\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... imilar '
'low-friction transition to primary system.\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... s: AWS Platform, '
'NHSD, Contact Centre Development\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... ments were now '
'aligned, enhancing standardisation\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... the highest '
'across all teams - tech and non-tech\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... es\n'
'- **Highlights:** Can’t divulge. Confidential.\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... ctive. Candidate '
'selection as positively affected\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... ered in relatively '
'short period and within budget\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... ights:** Enabled '
'team to deliver at a rapid pace.\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... MS Teams with '
'custom features not available COTS)\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... mal **saving 50K '
'USD per annum in license fees.**\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... abilities that '
'often required custom development.\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... : July 6, 2020 → '
'February 5, 2021** (Tech work):\n'
'\n')
--------------------
('# Healthdirect Australia\n'
'## Principal Engineer - Dat ... ect saved annual recurring license fees by '
'50K USD')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... ption:** Developed '
'various backend API components\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... d Typescript into '
'the team development workflow**\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... :** '
'**Trailblazer** in successful NLU application\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... ectives. Was '
'rolled out for various NSW hospitals\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... ough vendors like '
'HealthEngine, HotDoc and others\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... to pave its way '
'into adoption in the organisation\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... all solutions '
'applying best-in-class principles**\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... rential treatment '
'towards granting new projects**\n')
--------------------
('Regarding my work at **Healthdirect Australia** as ** ... : December 4, 2017 '
'→ July 3, 2020** (Tech work):\n'
'\n')
--------------------
('# Healthdirect Australia\n'
'## Sr. Software Developer - ... sign with advanced cloudformation based '
'automation')
--------------------
('# Insight Timer\n'
'📍Sydney, Australia \n'
'Sr. Software Eng ... ineer \n'
'Dates: February 4, 2017 → December 4, 2017')
--------------------
('Regarding my work at **Insight Timer** as **** (Tech ... ucing cost by '
'lowering dependency on AWS services\n')
--------------------
('Regarding my work at **Insight Timer** as **** (Tech ... adopted Kotlin '
'over java for new implementations\n')
--------------------
('# Insight Timer\n'
'### Other highlights or remarks\n'
'- Go ... ng, REST API design, RxJava/Java and System design')
--------------------
('# Autodesk Canada\n'
'📍Toronto, Canada \n'
'Sr. Java Develop ... eloper \n'
'Dates: January 2, 2012 → January 18, 2017')
--------------------
('Regarding my work at **Autodesk Canada** as **** (Tec ... end supporting the '
'popular Fusion360 product line\n')
--------------------
('Regarding my work at **Autodesk Canada** as **** (Tec ... outputs across '
'geo-distributed development teams\n')
--------------------
('Regarding my work at **Autodesk Canada** as **** (Non ... pplied:** '
'Organisation, team working, recruitment\n')
--------------------
('Regarding my work at **Autodesk Canada** as **** (Non ... velocity '
'frictions\n'
'- **Skills Applied:** Outreach\n')
--------------------
('# Autodesk Canada\n'
'### Other highlights or remarks\n'
'- G ... remarks\n'
'- Go to person for HATEOAS REST API design')
--------------------
('# University of Iowa\n'
'📍Iowa City, Iowa, USA \n'
'Applicat ... oper \n'
'Dates: December 1, 2008 → December 15, 2011')
--------------------
('Regarding my work at **University of Iowa** as **** ( ... col, and CORS for '
'creating well behaving web apps\n')
--------------------
('# University of Iowa\n'
'### Tech work\n'
'Exposed a web-appl ... t graduates in the development of jQuery mobile. |')
--------------------
('Regarding my work at **University of Iowa** as **** ( ... edge sharing\n'
'- **Highlights:** Recruited speakers\n')
--------------------
('# University of Iowa\n'
'### Other highlights or remarks\n'
' ... rapport with stakeholders during Business Analysis')
--------------------
('# ACT Incorporated\n'
'📍Iowa City, Iowa, USA \n'
'Staff Anal ... alyst \n'
'Dates: October 1, 2007 → November 26, 2008')
--------------------
('Regarding my work at **ACT Incorporated** as **** (Te ... equirements '
'gathering from resident Test Authors.\n')
--------------------
('Regarding my work at **ACT Incorporated** as **** (No ... ent CMS\n'
'- **Description:** Requirements gathering\n')
--------------------
('# D2 Hawkeye Pvt Ltd\n'
'📍Kathmandu, Nepal \n'
'Java Develop ... \n'
'Java Developer \n'
'Dates: May 1, 2005 → May 1, 2006')
--------------------
('Regarding my work at **D2 Hawkeye Pvt Ltd** as **** ( ... ort engine became '
'one of their flagship offerings\n')
--------------------
('Regarding my work at **D2 Hawkeye Pvt Ltd** as **** ( ... Created '
'internal-use SOAP API endpoints for data.\n')
--------------------
('Regarding my work at **D2 Hawkeye Pvt Ltd** as **** ( ... with US staff\n'
'- **Highlights:** Met key deadlines\n')
--------------------
('# Self Employed\n'
'📍Kathmandu, Nepal \n'
'Visual Basic 6 De ... Developer \n'
'Dates: December 1, 2004 → May 1, 2005')
--------------------
('Regarding my work at **Self Employed** as **** (Tech ... rything in '
'between, including support/maintenance\n')
--------------------
('Regarding my work at **Self Employed** as **** (Non T ... gathering, Price '
'negotiation, Contract securement\n')
--------------------
('# Personal Mini Project & Hobbies\n'
'- Q&A (RAG) text bo ... lajs-mastermind-game) \n'
'- Tech: ScalaJs, HTML, CSS')
--------------------
('# Training/Certifications/Courses\n'
'- Generative AI wit ... unctional Programming in Haskell - January 4, 2016')
--------------------
('# Education\n'
'- Masters - Computer Science \n'
'Maharishi ... ieeexplore.ieee.orgstampstamp.jsparnumber1310247))')
Save chunks as json¶
Now let's save these chunks as json
data_to_save = [
{"text": chunk} for chunk in markdown_chunks
] # Placeholder for embedding step
output_filename = os.path.join(
"prepared_data_faiss", f"{cv_source_markdown_file_name}.chunks.json"
)
# Create directory structure if it doesn't exist
os.makedirs("prepared_data_faiss", exist_ok=True)
with open(output_filename, "w") as f:
json.dump(data_to_save, f, indent=2)
print(
f"💾 Mock data saved to '{output_filename}'. Next step would be to add embeddings."
)
💾 Mock data saved to 'prepared_data_faiss/cv-2025-06-01.md.chunks.json'. Next step would be to add embeddings.
The career data is naturally grouped into semantic elements. Hence adopted this chunking strategy instead of a RecursiveCharacterTextSplitter.
Embedding¶
Next we will add these chunks into the vector index so that they can be semnatically retrieved later
class CVFaissEmbedder:
def __init__(self, model_name: str = "sentence-transformers/all-MiniLM-L6-v2"):
self.model = SentenceTransformer(model_name)
self.index = None
self.chunks = []
self.dimension = 384 # dimension for "sentence-transformers/all-MiniLM-L6-v2"
def load_chunks(self, chunks_json_file: str) -> List[Dict]:
with open(chunks_json_file, "r") as f:
self.chunks = json.load(f)
return self.chunks
def create_embeddings(self) -> np.ndarray:
"""Create embeddings for all chunks"""
embeddings = self.model.encode(self.chunks, convert_to_numpy=True)
return embeddings
def build_index(self, embeddings: np.ndarray):
"""Build FAISS index"""
self.index = faiss.IndexFlatIP(self.dimension)
faiss.normalize_L2(embeddings)
self.index.add(embeddings)
def save_index(self, file: str = "cv_index.faiss"):
faiss.write_index(self.index, file)
print(f"Saved index to {file}")
def load_index(self, file: str = "cv_index.faiss"):
self.index = faiss.read_index(file)
print(f"Loaded index from {file}")
def search(self, query: str, num_chunks_to_retrieve: int = 3) -> List[Dict]:
query_embeds = self.model.encode([query], convert_to_numpy=True)
faiss.normalize_L2(query_embeds)
# search
scores, indices = self.index.search(query_embeds, num_chunks_to_retrieve)
# map to chunks from indices
results = []
for idx, score in zip(indices[0], scores[0]):
chunk = {}
if idx < len(self.chunks): # safety check
chunk["content"] = str(self.chunks[idx]) # .copy()
chunk["relevance_score"] = float(score)
results.append(chunk)
return results
Perform embedding¶
Now let's do the embedding
cv_embeds = CVFaissEmbedder()
cv_embeds.load_chunks(output_filename)
embeddings = cv_embeds.create_embeddings()
print(embeddings)
print("Now building FAISS index")
cv_embeds.build_index(embeddings)
embeddings_filename=f"{output_filename}.faiss"
cv_embeds.save_index(embeddings_filename)
[[-0.01746857 -0.01386396 0.00048448 ... -0.03198443 -0.00998253 0.00830058] [-0.05188219 0.02842885 0.04710363 ... -0.06577165 0.06617153 0.05583187] [-0.09246843 0.09975132 -0.04714889 ... -0.06883582 0.01592954 0.05648626] ... [-0.10956752 -0.02698764 -0.00150927 ... -0.02031867 0.0445997 0.04409875] [-0.05473209 -0.06764245 0.05323834 ... 0.01342495 -0.00667846 -0.00751785] [-0.05910152 0.06252933 -0.0561499 ... -0.01943959 -0.02822687 0.0874305 ]] Now building FAISS index Saved index to prepared_data_faiss/cv-2025-06-01.md.chunks.json.faiss
Test semantic retrieval¶
Now let's test vector index retrieval to see how well it matches
print("Work history:\n")
pprint(cv_embeds.search('work history'))
print("-" * 20)
print("Background:\n")
pprint(cv_embeds.search('Background'))
print("-" * 20)
Work history:
[{'content': "{'text': 'Regarding my work at **Healthdirect Australia** as "
'**Sr. Software Developer - Dates: December 4, 2017 → July 3, '
'2020** (Tech work):\\n\\n- **Job Title:** Sr. Software '
'Engineer\\n- **Work/Project:** CMS API development\\n- '
'**Technology Used:** Java 8, Alfresco, PoolParty (RDF)\\n- '
'**Skills Applied:** Integration\\n- **Description:** Developed '
"various backend API components\\n'}",
'relevance_score': 0.41815584897994995},
{'content': "{'text': 'Regarding my work at **Autodesk Canada** as **** (Non "
'Tech work):\\n\\n- **Work/Project:** Cross-geo hackathons\\n- '
'**Description:** Organised 2 such yearly hackathons\\n- **Skills '
"Applied:** Organisation, team working, recruitment\\n'}",
'relevance_score': 0.4164963662624359},
{'content': "{'text': 'Regarding my work at **Healthdirect Australia** as "
'**Sr. Software Developer - Dates: December 4, 2017 → July 3, '
"2020** (Tech work):\\n\\n'}",
'relevance_score': 0.40159571170806885}]
--------------------
Background:
[{'content': "{'text': '# Autodesk Canada\\n### Other highlights or "
"remarks\\n- Go to person for HATEOAS REST API design'}",
'relevance_score': 0.21256308257579803},
{'content': "{'text': '# Personal Mini Project & Hobbies\\n- Q&A (RAG) text "
'bot that answers questions based on my CV (April 15, 2025) \\n- '
'Atlassian Forge Plugin (December 23, 2024): \\n- A plugin for '
'Confluence to create/update/edit Lean Canvas \\n- Tech: React, '
'Typescript, mobx, Atlassian Forge \\n- Simple Agentic '
'researcher (February 11, 2024 - Github link: '
'https://github.com/ffos/llm-agentic-search) \\n- Supervisor '
'agent accepted user query and produced a research report '
'delegating to sub-agents to using DuckDuckGo as “tool” \\n- '
'Tech: Langchain (Python), OpenAI (LLM) \\n- Woodworking and '
'indoor furniture making (Attained TAFE Cert II - November 1, '
'2023 ) \\n- “Mastermind” game running on browser (November 27, '
'2016 - Github link: '
'https://github.com/ffos/scalajs-mastermind-game) \\n- Tech: '
"ScalaJs, HTML, CSS'}",
'relevance_score': 0.2050330638885498},
{'content': "{'text': '# Education\\n- Masters - Computer Science "
'\\nMaharishi International University \\nIowa, USA \\nFebruary '
'1, 2006 → February 1, 2008 \\n- Bachelors - Computer '
'Engineering \\nInstitute of Engineering, Tribhuvan University '
'\\nLalitpur, Nepal \\nFebruary 1, 2000 → February 1, 2005 '
'\\nFinal project was IEEE CSIDC 2004 - World 10th '
'([CSIDC-Link-1](https://archive.md/OWLlZ), '
"[CSIDC-Link-2](https://archive.org/details/httpsieeexplore.ieee.orgstampstamp.jsparnumber1310247))'}",
'relevance_score': 0.1774899661540985}]
--------------------
Use LLM to return results¶
- Find matches for query using FAISS (the query needs to be embedded too so they lookup in the same vector space)
- Use the match to build the context for LLM to respond with
from langchain_core.messages import HumanMessage, SystemMessage
load_dotenv()
print(f"Open AI API Key string of length {len(os.getenv('OPENAI_API_KEY'))} now loaded")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.7, max_tokens=500)
def chat(query:str) -> dict[str,any]:
context_chunks = cv_embeds.search(query, num_chunks_to_retrieve=20)
context = "\n\n".join(c["content"] for c in context_chunks)
instruction = (
"You are an AI assistant representing a professional's CV."
"Answer questions based ONLY on the provided CV information within <CONTEXT> tags."
"Be concise, accurate and professional."
"If the information is not in the context, say so politely."
f"<Context>\n{context}\n</Context>\n\n"
"Response:"
)
messages = [
SystemMessage(content=instruction),
HumanMessage(content=query)
]
response = llm.invoke(messages)
return response.content
Open AI API Key string of length 164 now loaded
pprint(chat("Tell me about yourself"))
('Overall, I am quick to learn, embrace challenges, and lead by example. I '
'adapt quickly, provide value, and am optimistic and friendly in my approach.')
output = chat("list all the company names you worked along with date ranges. Output json.")
parsed_json = json.loads(output)
print(json.dumps(parsed_json, indent=2))
{
"companies": [
{
"name": "Healthdirect Australia",
"date_range": "December 4, 2017 - Present"
},
{
"name": "Self Employed",
"date_range": "December 1, 2004 - May 1, 2005"
},
{
"name": "University of Iowa",
"date_range": "December 1, 2008 - December 15, 2011"
},
{
"name": "Autodesk Canada",
"date_range": "January 2, 2012 - January 18, 2017"
},
{
"name": "ACT Incorporated",
"date_range": "October 1, 2007 - November 26, 2008"
},
{
"name": "D2 Hawkeye Pvt Ltd",
"date_range": "May 1, 2005 - May 1, 2006"
},
{
"name": "Insight Timer",
"date_range": "February 4, 2017 - December 4, 2017"
}
]
}
output = chat("List all the company names you worked and the technologies used in each. Output json.")
parsed_json = json.loads(output)
print(json.dumps(parsed_json, indent=2))
{
"work_experience": [
{
"company_name": "Healthdirect Australia",
"technologies_used": [
"Java 8",
"Alfresco",
"PoolParty (RDF)",
"NodeJs/Typescript",
"MithrilJs",
"Snips-AI (Python)",
"AWS Lambda",
"API Gateways",
"Cloudformation"
]
},
{
"company_name": "D2 Hawkeye Pvt Ltd",
"technologies_used": [
"Java & Servlets",
"Axis2",
"Apache POI",
"Oracle 10g",
"SOAP"
]
},
{
"company_name": "University of Iowa",
"technologies_used": [
"Java",
"Jersey Framework",
"Stripes Framework",
"Hibernate ORM",
"Oracle DB",
"JSP",
"jQuery",
"prototype-js",
"scriptaculous-js",
"Groovy",
"Oracle DB",
"jQuery mobile"
]
},
{
"company_name": "Autodesk Canada",
"technologies_used": [
"Java 8",
"Postgres",
"Jersey",
"Antlr4",
"Spring",
"Hibernate",
"ElasticSearch",
"JBehave",
"Angular JS",
"Apache Tomcat",
"Linux deployments on AWS EC2s"
]
}
]
}